s
i
n
g
u
l
a
r
i
t
y
RL Adventures with Garry

Recently, I created Garry for a class at Columbia. This robot gave me the perfect platform to test some RL algorithms I had picked up. However, to simulate the robot, I wanted to use MuJoCo. There was no "easy" way to get the 3D CAD of Garry loaded in MuJoCo. There was a handy tool that converted a Solidworks Assembly into an URDF file, which could then be turned into an XML file by MuJoCo. However, this tool does not account for passive joints. To get the passive joints to work, I had to export two separate models: one with the location of the passive joint as the actual joint, and the other with the location of the regular joint. I could then use the coordinates of the passive joints to create an equality joint in the XML file.
After loading Garry into MuJoCo, the RL implementation was quite straightforward. I created a function that progressed one step in the simulation, with syntax equivalent to OpenAI's Gym's step function. The actual RL implementation can be found on my GitHub: https://github.com/wwangg22/rl_robot/tree/main. The basic gist is using TD3 to train on batches in the ReplayBuffer. However, the most interesting part of the RL implementation is implementing the reward function, which is what I am going to be primarily talking about. In the step function, I had to decide how I was going to give rewards, which turned out to be the hardest part of training the RL algorithm. At first, I thought that if I just rewarded the robot based on how far it could move in the x direction, it might lead to discovering creative gaits. The termination condition was quite simple: as soon as there is contact between any part of the robot other than the feet and the ground, the simulation ends. However, this prompted a jumping behavior.

The robot would start by taking a step, but when it tried to take another step, it would always fall. So instead of trying to figure out how to take that next step, the agent started optimizing how far it could jump before falling.
Instead of just rewarding movement in x direction, I also decided to penalize orientation differences from an upright position. However, this produced an overly-cautious agent. Rather than taking a new step, it ended up slowing hopping on one foot while keeping the other foot in the air.

I realized the agent was having a hard time keeping its feet flat on the ground, so I created another model where I removed the joint at the ankle and replaced it with a ball. I thought this would help the agent discover a stable gait., and then I could simply program the feet to remain parallel to the ground at all times.
This did help with stability, but it did not solve the underlying problem. The robot was able to move by taking baby steps, but it was still overly-cautious. However, after fine-tuning the rewards a bit more, I finally got semi-successful walk:
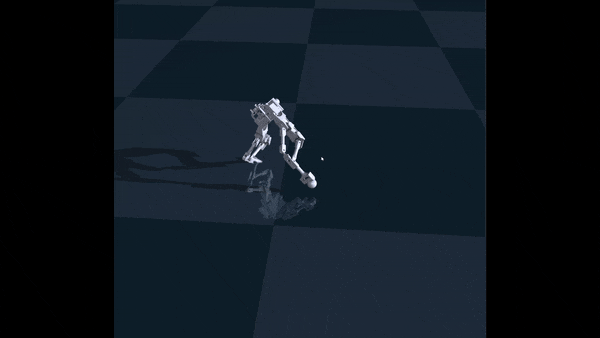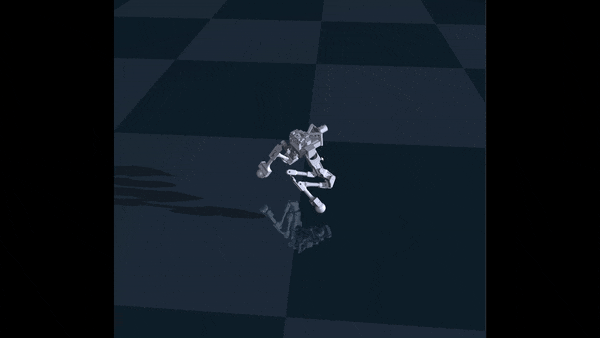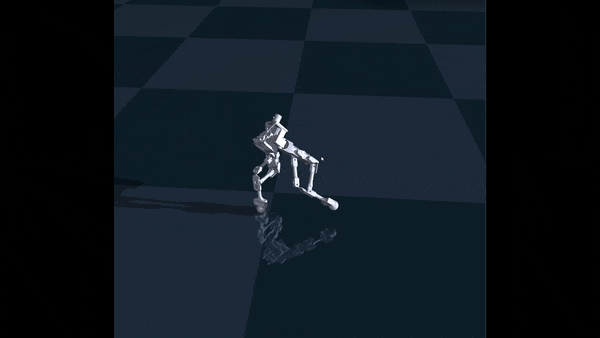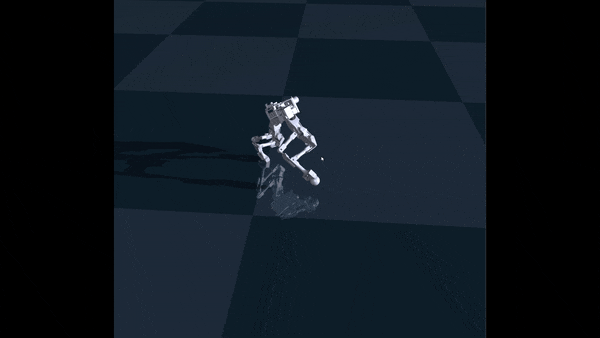
My adventures with Garry ended there, mostly because the servos on Garry could not handle torque control, and my model I trained outputs values in torque control. It was therefore impossible to run my model on Garry. However, I am building another robot with real torque control, so my adventures with RL lives on.