s
i
n
g
u
l
a
r
i
t
y
Clash Royale AI
I’m writing this blog post retrospectively. I’ve always wanted to build an AI agent for Clash Royale, but back then I didn’t really understand AI well enough to figure out how to apply it. Now that I’ve tried multiple reinforcement learning (RL) algorithms on different projects—and winter break was starting—I thought, “Why not give it a shot?”
Clash Royale AI isn’t exactly a new idea; plenty of people have attempted it before. A quick search online will show several examples of these “AI” models that use an object detection algorithm (like YOLO) to grab the state of the game from the screen, then rely on a hard-coded script (basically a bunch of if statements) to decide which card to place. Calling that a “real AI” felt like a stretch to me. I wanted a deep learning model to serve as the brain. I ended up choosing PPO (Proximal Policy Optimization), partly because it’s the same model OpenAI used to beat world champions in Dota 2.
However, OpenAI had privileged access to the Dota 2 game states through an API, and I don’t have that for Clash Royale. So, to get the game state, I had two options: either crack the game and expose the API, or go with a vision-based approach. I initially tried the game-cracking route (with some Frida experience), but the obfuscated code was too complicated to reverse engineer. Fortunately, while researching, I discovered that people had reverse-engineered an old Clash Royale server from 2017. I hoped it might include a game engine I could exploit, but it turned out all the game logic is on the client side—the server just synchronizes messages between two clients. Still, I managed to create a private server backdoor that could help automate certain things for training (like placing cards, starting battles, etc.).
That left me with the problem of extracting the game state, which ultimately meant using a YOLO model for object detection. Training YOLO can be tedious because of all the image labeling. But since Clash Royale troops are basically just sprites placed on a board, I realized I could generate synthetic training images using the actual troop sprites. I made around 2,000 artificially generated images for initial training. However, the model was too sensitive to noise—things like confetti, clouds, and color changes when troops take damage led to false positives. To combat this, I added random color shading to the troops and dropped in random non-troop sprites into the images. That helped a bit, but I still needed more fine-tuning. This is what a generated sprite image looked like:
Once I had a semi-decent base model, I used it to label real gameplay images, then I corrected those labels by hand. After every 200 or so images, I’d retrain the model and repeat. Eventually, I labeled around 1,100 real gameplay images and trained a fresh model using just those. This became the first iteration of my Clash Royale AI. Actually, I trained two YOLO models: one for detecting which cards are in your deck (so you know which cards are available to place) and another one for troops on the battlefield. On top of that, I used template matching to find tower health and simple pixel-range checks for elixir count. This is what it looked like:
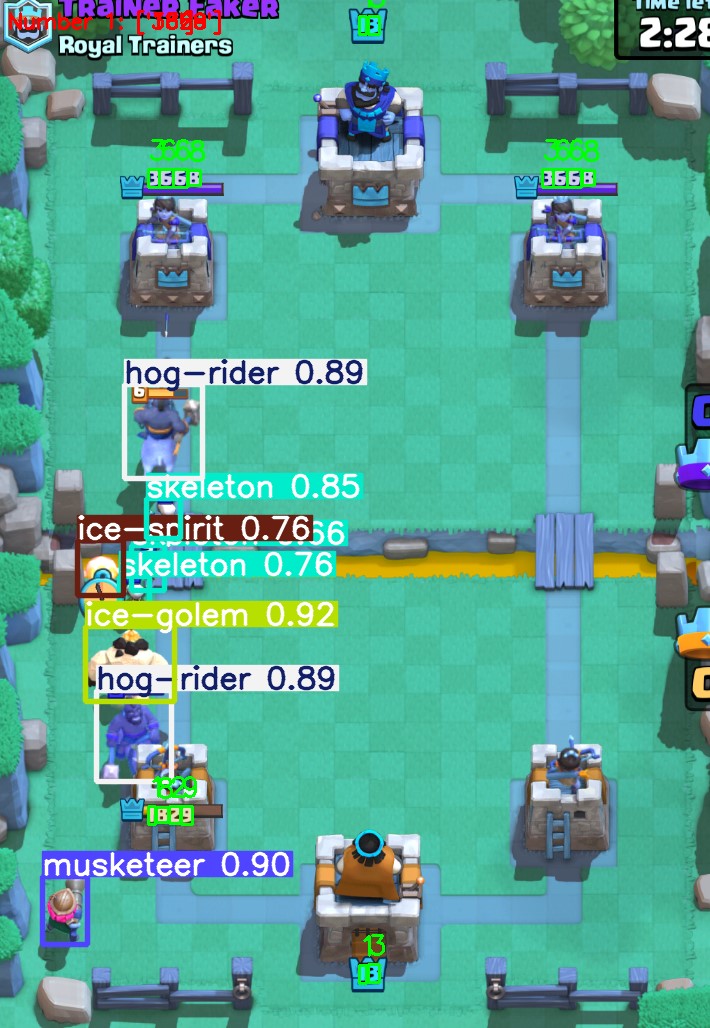
Ignore the weird colors. CV2 displays images in BGR format, and I did not change it before displaying it.
At this point, I had some design choices to make. YOLO can return an arbitrary number of detections, but my PPO input has a fixed size. I decided to limit the number of troops I’d pass into the model to 10. This worked okay until double elixir time, when there can easily be more than 10 troops on the board. I could have increased the limit to 20, but it felt wasteful in the early game. Instead, I fed the raw image into a pretrained ResNet-18 to get a feature vector, then concatenated that vector with deck and elixir information before giving it to the PPO agent. I didn’t get to train it for many steps (online training is expensive), so I can’t say how well it truly performed.
I also want to talk briefly about the model’s outputs. In Clash Royale, you generally have two decisions: which troop to place (or not place) and where to place it. These aren’t independent choices—some troops can only be placed in certain areas at certain times. One approach is to let the model choose illegal actions occasionally, punish it, and hope it learns. But that wastes whole timesteps on invalid moves. The other approach is a fully discrete action space where I mask out illegal actions, so the model never tries them. I chose the latter. It keeps the model from making wasted moves, but complicates training. Because the second action (placement) depends on which troop was selected first, I have to apply different masks for each troop choice. This is a nightmare for batch training in PPO since I need log probabilities for each action under the current policy. Ultimately, I ended up iterating through the first actions instead of grouping them in a batch, mostly to avoid underrepresenting certain actions.
Anyway, enough of the technical details—here are some clips of the model in action.
This is still an ongoing project, and I do plan to make some improvements to improve sample efficiency.