SNAP-AR3D
SnapAR3D uses AR guidance to help you capture optimal photos of an object while recording precise camera poses. Those poses are then converted into NeRF-compatible matrices and fed into NVIDIA nvdifrec to produce detailed 3D reconstructions.
Project Demo
Project Story
Our goal was a pipeline that turns phone videos into textured 3D meshes in minutes. By capturing ARKit poses we bypass COLMAP, halving reconstruction time, and feed images + poses to NVIDIA NVDiffRec for photorealistic output. The whole flow ships as a one-tap iOS app: capture → model → GLTF export.
Technical Details
NVDiffRec (img-to-mesh)
We built on Nvidia’s NVDiffRec paper. The original method trains ~1 hour on a V100; we needed ~10 minutes on a laptop 3080 while keeping quality high.
Early high-res meshes were spiky, so we increased the Laplace-scale regularizer to suppress sharp changes between vertices. Because most objects are fairly smooth, a larger value—especially early in training— produced visibly better results.
Tuning resolution + regularizer let us achieve solid reconstructions in 10 minutes. The loss curve is shown below.

The HDR map captures scene lighting; Kd, Korm, and the normal map are the recovered object textures.
ARKit Built-in SLAM
A standard pipeline overview is shown below.
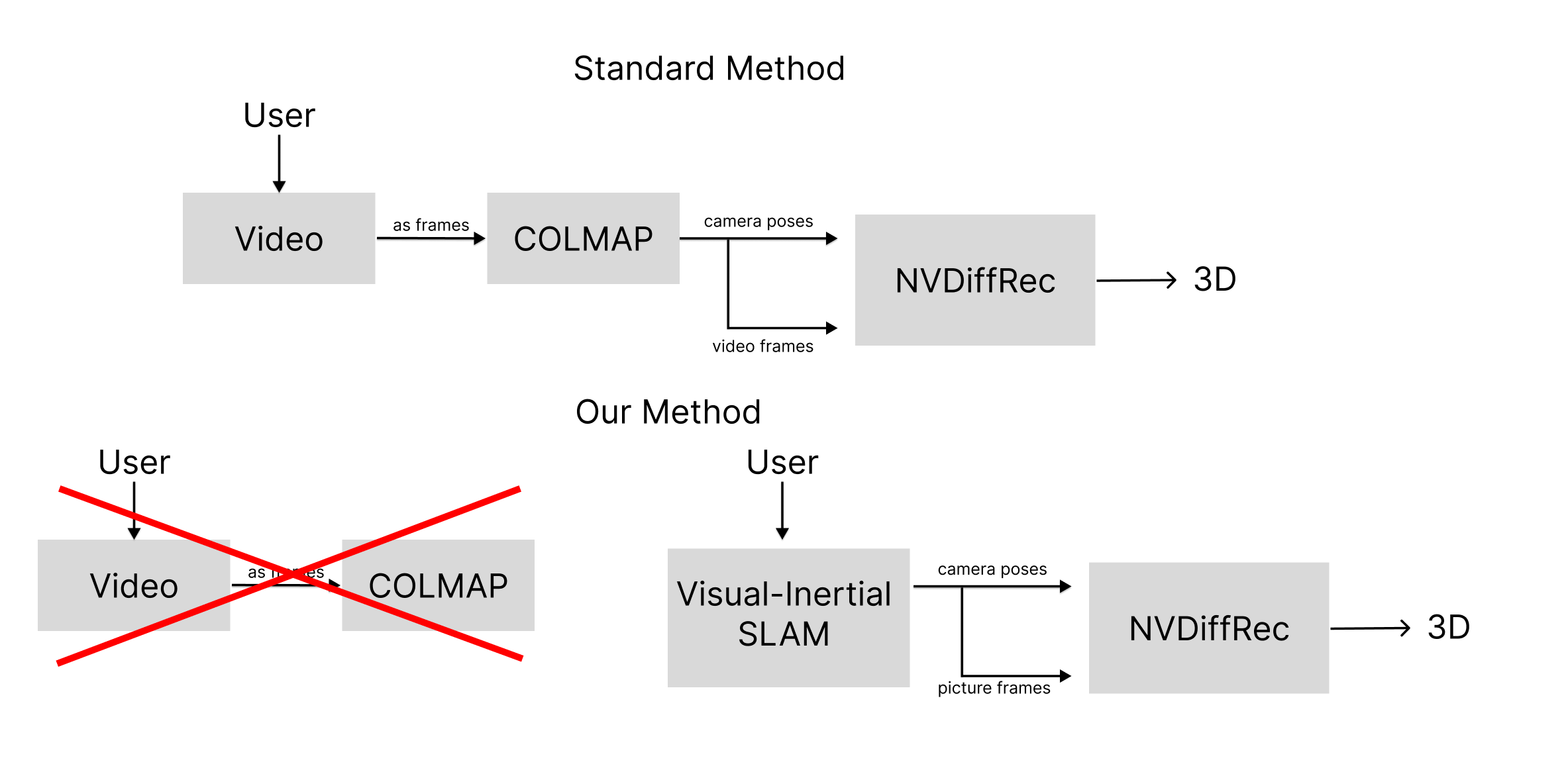
Traditionally, users run COLMAP on videos to extract camera poses, but it often fails with objects on plain white surfaces because there aren’t enough background features to verify transformations.
ARKit’s SLAM provides continuous poses, yet its image quality can vary. To guarantee crisp frames we built a Swift UI that overlays a tiled sphere on the object: users align the camera with each tile until it disappears, ensuring uniform, high-quality coverage.
Repeating this interaction yields a robust photo set and poses for reconstruction. A full demo appears in the video above.
This project was developed during the TreeHacks hackathon.